---
url: 'https://www.ipfoxy.net/blog/use-cases/5788'
title: 2026最新数据抓取实战:如何用 ChatGPT 实现网页数据抓取?
date: '2026-04-14T18:15:34+08:00'
modified: '2026-04-15T10:40:22+08:00'
type: post
summary: 2026最新网页数据抓取实战教程,教你用ChatGPT实现从代码生成到API采集的完整流程,并解决反爬与动态网页抓取问题。
categories:
- 使用场景
tags:
- ChatGPT
- ChatGPT 网页数据抓取
published: true
---
# 2026最新数据抓取实战:如何用 ChatGPT 实现网页数据抓取?
文章大纲
[
一、为什么要借助ChatGPT做网页数据抓取?
](#yi_wei_shen_me_yao_jie_zhuChatGPT_zuo_wang_ye_shu_ju_zhua_qu)
[
二、ChatGPT 辅助编写网页抓取的7种用途
](#erChatGPT_fu_zhu_bian_xie_wang_ye_zhua_qu_de7zhong_yong_tu)
[
1.用 ChatGPT 生成网页抓取脚本
](#1_yong_ChatGPT_sheng_cheng_wang_ye_zhua_qu_jiao_ben)
[
2.使用 Selenium / Playwright 抓取动态网页
](#2_shi_yong_Selenium_Playwright_zhua_qu_dong_tai_wang_ye)
[
3.从复杂网页结构中提取数据
](#3_cong_fu_za_wang_ye_jie_gou_zhong_ti_qu_shu_ju)
[
4.自动处理分页与批量抓取数据
](#4_zi_dong_chu_li_fen_ye_yu_pi_liang_zhua_qu_shu_ju)
[
5.通过 API 接口抓取网页数据
](#5_tong_guo_API_jie_kou_zhua_qu_wang_ye_shu_ju)
[
6. 使用 Flask 构建爬虫 API,实现数据服务化
](#6_shi_yong_Flask_gou_jian_pa_chong_API_shi_xian_shu_ju_fu_wu_hua)
[
7.使用 ChatGPT 自动生成 XPath / CSS 选择器
](#7_shi_yong_ChatGPT_zi_dong_sheng_cheng_XPath_CSS_xuan_ze_qi)
[
三、使用 ChatGPT 编写网页抓取脚本会遇到哪些问题?
](#san_shi_yong_ChatGPT_bian_xie_wang_ye_zhua_qu_jiao_ben_hui_yu_dao_na_xie_wen_ti)
[
1. 无法直接访问实时网页数据
](#1_wu_fa_zhi_jie_fang_wen_shi_shi_wang_ye_shu_ju)
[
2. 生成代码可能不稳定或不完整
](#2_sheng_cheng_dai_ma_ke_neng_bu_wen_ding_huo_bu_wan_zheng)
[
3. 难以应对网站反爬机制
](#3_nan_yi_ying_dui_wang_zhan_fan_pa_ji_zhi)
[
4. 动态网页与复杂交互处理能力有限
](#4_dong_tai_wang_ye_yu_fu_za_jiao_hu_chu_li_neng_li_you_xian)
[
5. 缺乏长期稳定运行能力
](#5_que_fa_zhang_qi_wen_ding_yun_xing_neng_li)
[
四、ChatGPT数据抓取:如何提高网页爬取稳定性?
](#siChatGPT_shu_ju_zhua_qu_ru_he_ti_gao_wang_ye_pa_qu_wen_ding_xing)
[
1. 结合实际执行工具完成数据抓取
](#1_jie_he_shi_ji_zhi_xing_gong_ju_wan_cheng_shu_ju_zhua_qu)
[
2. 优化代码生成与调试流程
](#2_you_hua_dai_ma_sheng_cheng_yu_diao_shi_liu_cheng)
[
3. 使用动态住宅 IP 应对反爬机制
](#3_shi_yong_dong_tai_zhu_zhai_IP_ying_dui_fan_pa_ji_zhi)
[
4. 动态IP轮换与粘性会话
](#4_dong_taiIP_lun_huan_yu_zhan_xing_hui_hua)
[
5. 构建自动化与长期运行能力
](#5_gou_jian_zi_dong_hua_yu_zhang_qi_yun_xing_neng_li)
[
四、常见问题与解答
](#si_chang_jian_wen_ti_yu_jie_da)
[
五、总结
](#wu_zong_jie)
2026 年,网页数据抓取已经成为电商分析、SEO优化与市场研究的重要基础能力。随着 ChatGPT 等AI工具的普及,网页抓取的门槛被大幅降低,越来越多用户开始借助 AI 来生成代码、优化逻辑并加速数据采集流程。
本文将系统讲解如何利用 ChatGPT 从零开始实现网页数据抓取,包括实战方法、常见场景、技术局限以及解决方案,帮助你快速构建一套高效的数据采集体系。
## **一、**为什么要借助ChatGPT做网页数据抓取?
随着 AI 技术的发展,网页数据抓取正在从“技术门槛较高的开发工作”,逐渐转变为“人人可用的效率工具”。越来越多用户选择借助 ChatGPT,本质上是因为它显著提升了抓取效率并降低了使用难度。
主要原因包括:
- **降低技术门槛**:无需深厚编程基础,也能快速上手网页抓取
- **支持调试与优化**:代码报错可快速修复与迭代
- **扩展能力强**:可结合 Python、Selenium、API 等技术
- **应用场景广泛**:适用于电商、SEO、数据分析等多个领域
## **二、**ChatGPT 辅助编写网页抓取的7种用途
下面整理了7种最常见、最实用的用 ChatGPT 辅助编写爬虫代码的类型,覆盖从入门到进阶的完整流程。
### ** 1.用 ChatGPT 生成网页抓取脚本**
ChatGPT 可以快速生成基础的网页抓取脚本,通常基于 Python 的 `requests` 和 `BeautifulSoup` 库。你只需要提供目标网址和需要提取的数据字段即可。
ChatGPT指令:请编写一个 Python 脚本,从以下网址抓取商品标题和价格:xxxxxx
代码:
```
import requests
from bs4 import BeautifulSoup
url = "xxxxxxxx"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
products = soup.select(".product-card")
for product in products:
title = product.select_one("h4").get_text(strip=True)
price = product.select_one(".price-wrapper").get_text(strip=True)
print(f"标题: {title}, 价格: {price}")
```
### ** 2.使用 Selenium / Playwright 抓取动态网页**
对于 JavaScript 渲染的网站,普通请求无法获取完整数据。此时可以借助 ChatGPT 生成 Selenium 或 Playwright 脚本,实现浏览器自动化抓取。
**ChatGPT指令:**
请使用 Selenium 编写一个 Python 脚本,抓取动态加载网页中的商品标题
**代码:**
```
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://example.com")
time.sleep(3)
titles = driver.find_elements(By.CSS_SELECTOR, ".product-title")
for t in titles:
print(t.text)
driver.quit()
```
### ** 3.从复杂网页结构中提取数据**
当网页结构复杂(如嵌套标签或表格)时,可以让 ChatGPT 自动分析 HTML 并提取所需数据。
**ChatGPT指令:**
请根据以下HTML结构提取商品名称、价格和评分
**代码:**
```
from bs4 import BeautifulSoup
html = """商品A
$10"""
soup = BeautifulSoup(html, "html.parser")
name = soup.select_one("h2").text
price = soup.select_one(".price").text
print(name, price)
```
### ** 4.自动处理分页与批量抓取数据**
对于多页数据,可以让 ChatGPT 自动生成分页抓取逻辑,实现批量采集。
**ChatGPT指令:**
写一个Python脚本,抓取某网站前5页的商品数据
**代码:**
```
import requests
from bs4 import BeautifulSoup
for page in range(1, 6):
url = f"https://example.com/page/{page}"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
items = soup.select(".item")
for item in items:
print(item.text)
```
### ** 5.通过 API 接口抓取网页数据**
很多网站的数据来自 API,使用 ChatGPT 可以分析接口并生成请求代码。
**ChatGPT指令:**
写一个Python脚本,请求API接口并获取JSON数据
**代码:**
```
import requests
url = "https://api.example.com/data"
response = requests.get(url)
data = response.json()
for item in data:
print(item)
```
### **6. 使用 Flask 构建爬虫 API,实现数据服务化**
当需要将爬虫结果提供给其他系统时,可以使用 ChatGPT 生成 Flask API 服务。
**ChatGPT指令:**
使用Flask创建一个API接口,返回爬虫抓取的数据
**代码:**
```
from flask import Flask, jsonify
app = Flask(__name__)
@app.route("/data")
def get_data():
data = {"name": "商品A", "price": 10}
return jsonify(data)
app.run(debug=True)
```
### ** 7.使用 ChatGPT 自动生成 XPath / CSS 选择器**
在网页解析中,可以使用 ChatGPT 自动生成 XPath 或 CSS 选择器,提高数据提取效率。
**ChatGPT指令:**
根据以下HTML生成XPath,用于提取商品标题
**代码:**
```
from lxml import etree
html = """商品标题
"""
tree = etree.HTML(html)
title = tree.xpath("//h1/text()")
print(title)
```
## **三、**使用 ChatGPT 编写网页抓取脚本会遇到哪些问题?
虽然 ChatGPT 能显著提升网页抓取效率,但在实际项目中,它仍然存在一些不可忽视的局限性:
### 1. 无法直接访问实时网页数据
ChatGPT 本身不能直接抓取网页,它只能生成代码和提供思路,无法执行实际的数据采集任务。
### 2. 生成代码可能不稳定或不完整
在复杂场景下,生成的代码可能存在解析错误、逻辑不完整或无法适配网站结构的问题,需要人工调试。
### 3. 难以应对网站反爬机制
在抓取电商、社媒等网站时,常见问题包括:
- IP 被封禁
- 请求被拦截(403 / 429)
- 出现验证码验证
本质上,这些都是网站风控系统在限制爬虫行为。
### 4. 动态网页与复杂交互处理能力有限
对于需要登录、点击或滚动加载的页面,仅靠基础请求往往无法获取完整数据。
### 5. 缺乏长期稳定运行能力
ChatGPT 本身不具备运行环境,无法支持定时任务、自动监控和持续数据更新。
## **四、**ChatGPT数据抓取:如何提高网页爬取稳定性?
针对以上问题,我们可以通过结合不同工具与策略,构建更稳定的数据抓取系统:
### 1. 结合实际执行工具完成数据抓取
- 使用 Python(requests / BeautifulSoup)执行静态抓取
- 使用 Selenium / Playwright 处理动态网页
### 2. 优化代码生成与调试流程
- 分步骤提问
- 多轮优化 Prompt
- 根据真实网页结构手动调整代码
### 3. 使用动态住宅 IP 应对反爬机制
在实际抓取中,可以通过动态住宅 IP 提升稳定性:
- **真实住宅网络来源:**模拟真实用户访问,降低识别风险
- **支持多地区切换:**可模拟不同国家或地区访问,满足多场景数据采集需求
- **提升匿名性与隐私保护**:隐藏真实请求来源,增强安全性
例如,专业规模自动化团队会选择使用[**IPFoxy** ](https://app.ipfoxy.net/login?source=blog)的动态住宅代理服务,这类代理通常基于真实家庭宽带网络构建,具备高并发、高匿名性、低重复率和真实用户行为特征。相比普通数据中心 IP,这种 IP 更难被目标网站识别为爬虫流量,在应对风控系统和反爬机制时表现更稳定,从而显著提升数据抓取的成功率和持续性。
[点击前往免费试用IPFoxy](https://app.ipfoxy.net/login?source=blog)
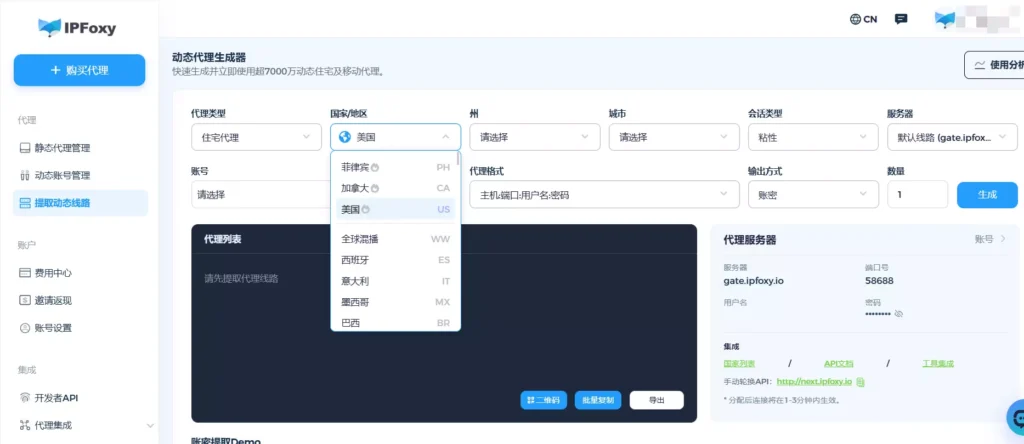
### 4. **动态IP轮换与粘性会话**
- **动态轮换 IP:**每次请求更换 IP,有效分散访问来源,避免因高频请求触发网站的封锁机制,提升整体抓取的连续性与稳定性
- **粘性会话:**在登录或翻页时保持同一 IP,在一定时间内维持稳定会话,避免因 IP 频繁变化导致登录状态失效或触发风控验证。
实际运用中,可以利用**[IPFoxy](https://app.ipfoxy.net/login?source=blog)动态代理服务提供的会话类型配置功能,**配置每次请求/粘性请求参数从而实现IP按需轮换,降低风控风险。
### 5. 构建自动化与长期运行能力
- 使用服务器部署爬虫程序
- 配合定时任务(cron)
- 构建数据采集系统(API + 数据存储)
## **四、常见问题与解答**
1.ChatGPT 可以直接爬取网站吗?
不可以。ChatGPT 本身不能直接访问或抓取网页数据,它的作用是生成代码和提供思路。实际数据抓取需要在 Python 等环境中运行。
2.使用 ChatGPT 做网页抓取合法吗?
是否合法取决于你的使用方式,而不是工具本身。合规的网页抓取应遵守网站规则、访问频率限制以及数据使用规范。ChatGPT 只负责辅助开发,合规责任在使用者。
3.ChatGPT 可以一次性处理成千上万个 URL 的抓取吗?
虽然 ChatGPT 无法直接运行大规模任务,但你可以要求它构建一个“异步并发模型”(如 Python 的 `asyncio` + `aiohttp`)。由 ChatGPT 提供高效的多线程代码架构,你只需在本地或云端部署运行即可实现海量数据采集。
## **五、总结**
通过本文你可以看到,ChatGPT 不仅能帮助生成爬虫代码,还能覆盖从数据解析、分页处理到API抓取的完整流程。但在实际生产环境中,真正稳定的抓取系统仍然需要结合代理IP、自动化工具以及合理的任务调度策略。